
Table of Contents
Have you ever wondered how Instagram can send data to your feeds, how X can update your tweets on the internet, or how your messages are transmitted on WhatsApp? In a world where billions of devices communicate and thousands of terabytes of data are transmitted, data serialization formats are the unsung hero on the internet.
What is Data Serialization?
As human-readable information is not understood by computers and is not suitable for transmission over network devices. In data serialization, the data objects (a structured representation of data) are converted into a stream of bytes for ease of transmission over network devices.
The opposite where the stream of bytes is converted into data objects is called data de-serialization, which is performed when the data is received by the receiver user.
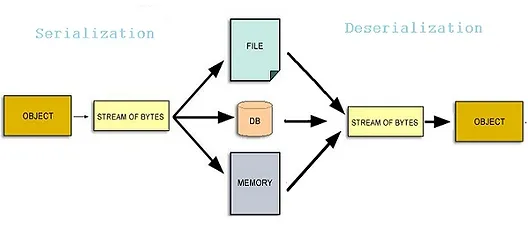
What are Data Serialization formats?
Now, let us consider my “X” post as a data object, this information cannot be directly transmitted over the network devices, so for this information to be transmitted we need to convert it into a specified format that can be JSON, XML or YAML and these formats are suitable for transportation, storage and reconstruction and hence are categorized as “data serialization formats”.
Now let us discuss each format one after the other
XML (eXtensible Markup Language)
The syntax is quite similar to HTML, but XML allows users to create custom tags, tags can have a hierarchy, and opening and closing tags, which allows the user to create tags with names and a hierarchy specific to their application or usage. As the data appears to be in a tree/ structured format it is human-readable and easy to understand.
The NETCONF (Network Configuration Protocol) which is used to manipulate, install and delete config files uses XML for data serialization and below is an NETCONF example usage of XML data serialization format.
<rpc message-id="101">
<get-config>
<source>
<running/>
</source>
<filter>
<interfaces>
<interface>
<name>GigabitEthernet0/0</name>
</interface>
</interfaces>
</filter>
</get-config>
</rpc>
Using XML we can create custom tags, but the problem is there can be XML tags that can conflict in an XML document, the XML namespace allows you to define XML tags that have the same name and different meanings and indeed helps in reducing conflicts. The XML namespace identifies each element/ tag with a URI (uniform resource identifier), each tag belongs to an URI. Suppose there is a tag “DoB” that can belong to two documents that store the DoB of two different categories of people, hence each DoB tag is identified by a different URI.
<item xmlns:person="http://example.com/person" xmlns:product="http://example.com/product">
<person:name>Ravi Sunder</person:name>
<product:name>Smartphone</product:name>
</item>
In the above example we created an XML namespace, using the xmlns keyword that defines two tags “person” and “product” are tags that belong to different namespaces, it is evident as they are identified by two different URI’s “http://example.com/person” for person and “http://example.com/product” for product. So this is how XML works and let’s head into our next format
JSON (JavaScript Object Notation)
JSON is a common file format for storing and transporting JavaScript objects and is common in API communication, the most popular example is the data of Instagram posts or X posts. The data is transmitted as arrays, key-value pairs etc which are usually inside JavaScript objects.
Below is an Instagram post example usage of JSON data serialization format.
{
"post_id": "123456789",
"username": "ravi_sunder",
"full_name": "Ravi Sunder",
"caption": "Loving the sunset view! 🌅 #sunset #nature",
"image_url": "https://example.com/images/sunset.jpg",
"likes": {
"count": 500,
"users": ["sneha_patel", "arvind_sharma", "priya_kumar"]
},
"hashtags": ["#sunset", "#nature"],
"timestamp": "2024-12-16T10:30:00Z"
}
In the above example of JSON, the “{}” brackets are used to determine an object, an object has key-value pairs where a key must be a string and a value can be of any data type. We can also see the likes object has two keys “count” which is 500 holding an integer value and “users” containing users who liked the post of the data type array.
For XML and JSON the system doesn’t care about whitespace and indentation and they are used only for human readability.
Now let’s proceed to our final data serialization format which is YAML.
YAML (YAML Ain’t a Markup Language)
Unlike the above two data serialization formats, YAML cares about whitespace and indentation, initially known as Yet Another Markup Language it was never a markup language and hence soon changed its abbreviation to “YAML Ain’t a Markup Language”.
YAML is commonly used for transporting and storing configuration files or devices and doesn’t store data in a document format like XML or JSON but instead as structured data. The most common application of YAML is in Ansible playbooks (for starters a playbook in Ansible is a configuration file written in YAML). Ansible is a common tool in the field of network automation.
YAML is also used in Cisco Python Automated Test Systems (PyATS) a framework for testing and automating network devices.
An Example usage of YAML in Ansible Playbook
---
- name: Install htop on target servers
hosts: all
become: true
tasks:
- name: Install htop
apt:
name: htop
state: present
With this, we conclude the article on data serialization formats. Read our top article here
[…] You can read about data serialization formats like YAML, XML, and JSON by clicking here! […]
[…] Data Serialization Formats, Explained! […]